Diagonalisasi Krylov Kuantum
Dalam pelajaran ini tentang diagonalisasi krylov kuantum (KQD) kita akan menjawab soalan-soalan berikut:
- Apakah kaedah Krylov secara umum?
- Kenapa kaedah Krylov berkesan dan dalam keadaan apa?
- Bagaimana pengkomputeran kuantum memainkan peranan?
Bahagian kuantum pengiraan ini sebahagian besarnya berdasarkan kerja dalam Ref [1].
Video di bawah memberi gambaran keseluruhan kaedah Krylov dalam pengkomputeran klasik, memotivasikan penggunaannya, dan menjelaskan bagaimana pengkomputeran kuantum boleh memainkan peranan dalam aliran kerja tersebut. Teks seterusnya menawarkan lebih banyak perincian dan melaksanakan kaedah Krylov secara klasik dan menggunakan komputer kuantum.
1. Pengenalan kepada kaedah Krylov
Kaedah subruang Krylov boleh merujuk kepada mana-mana daripada beberapa kaedah yang dibina di sekitar apa yang dipanggil subruang Krylov. Ulasan lengkap tentang ini adalah di luar skop pelajaran ini, tetapi Ref [2-4] boleh memberikan latar belakang yang lebih mendalam. Di sini, kita akan fokus pada apa itu subruang Krylov, bagaimana dan kenapa ia berguna dalam menyelesaikan masalah nilai eigen, dan akhirnya bagaimana ia boleh dilaksanakan pada komputer kuantum. Definisi: Diberikan matriks simetri, semi-definitif positif , ruang Krylov berdarjah ialah ruang yang dicakupi oleh vektor-vektor yang diperoleh dengan mendarabkan kuasa-kuasa lebih tinggi matriks , sehingga , dengan vektor rujukan .
Walaupun vektor-vektor di atas merentangi apa yang kita panggil subruang Krylov, tiada sebab untuk mengandaikan bahawa mereka akan berortogonal. Seseorang sering menggunakan proses pengortogonalan berulang yang serupa dengan pengortogonalan Gram-Schmidt. Di sini prosesnya sedikit berbeza kerana setiap vektor baru dibuat berortogonal dengan yang lain semasa ia dijana. Dalam konteks ini ia dipanggil iterasi Arnoldi. Bermula dengan vektor awal , seseorang menjana vektor seterusnya , dan kemudian memastikan vektor kedua ini berortogonal dengan yang pertama dengan menolak unjurannya pada . Iaitu
Kini mudah untuk melihat bahawa kerana
Kita lakukan perkara yang sama untuk vektor seterusnya, memastikan ia berortogonal dengan kedua-dua vektor sebelumnya:
Jika kita ulangi proses ini untuk semua vektor, kita mempunyai asas ortonormal lengkap untuk subruang Krylov. Perhatikan bahawa proses pengortogonalan di sini akan menghasilkan sifar apabila , kerana vektor berortogonal semestinya merentangi ruang penuh. Proses ini juga akan menghasilkan sifar jika mana-mana vektor adalah vektor eigen kerana semua vektor berikutnya akan menjadi gandaan vektor tersebut.
1.1 Contoh mudah: Krylov secara tangan
Mari kita lalui proses penjanaan subruang Krylov pada matriks yang sangat kecil, supaya kita dapat melihat prosesnya. Kita mulakan dengan matriks awal yang menjadi minat kita:
Untuk contoh kecil ini, kita boleh menentukan vektor eigen dan nilai eigen dengan mudah walaupun dengan tangan. Kita tunjukkan penyelesaian berangka di sini.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
Kita catat di sini untuk perbandingan kemudian:
Kita ingin mengkaji bagaimana proses ini berfungsi (atau gagal) apabila kita menambah dimensi subruang Krylov kita, . Untuk tujuan ini, kita akan menjalankan proses berikut:
- Jana subruang ruang vektor penuh bermula dengan vektor yang dipilih secara rawak (panggil ia jika ia sudah ternormal, seperti di atas).
- Unjurkan matriks penuh ke atas subruang tersebut, dan cari nilai eigen matriks unjuran .
- Tingkatkan saiz subruang dengan menjana lebih banyak vektor, memastikan ia ortonormal, menggunakan proses yang serupa dengan pengortogonalan Gram-Schmidt.
- Unjurkan ke atas subruang yang lebih besar dan cari nilai eigen matriks hasil .
- Ulangi ini sehingga nilai eigen menumpu (atau dalam kes mainan ini, sehingga kamu menjana vektor yang merentangi ruang vektor penuh matriks asal ).
Pelaksanaan biasa kaedah Krylov tidak perlu menyelesaikan masalah nilai eigen untuk matriks yang diunjurkan pada setiap subruang Krylov semasa ia dibina. Kamu boleh membina subruang berdimensi yang dikehendaki, unjurkan matriks ke atas subruang tersebut, dan diagonalisasikan matriks unjuran. Mengunjurkan dan mendiagonalisasikan pada setiap dimensi subruang hanya dilakukan untuk memeriksa konvergensi.
Dimensi :
Kita pilih vektor rawak, katakan
Jika ia belum ternormal, normalkan ia.
Kita kini mengunjurkan matriks kita ke atas subruang vektor tunggal ini:
Ini adalah unjuran matriks ke atas subruang Krylov kita apabila ia mengandungi hanya satu vektor, . Nilai eigen matriks ini secara trivial ialah 4. Kita boleh menganggap ini sebagai anggaran tertib sifar nilai eigen (dalam kes ini hanya satu) dari . Walaupun ia adalah anggaran yang lemah, ia adalah order magnitud yang betul.
Dimensi :
Kita kini menjana vektor seterusnya dalam subruang kita melalui operasi dengan pada vektor sebelumnya:
Sekarang kita tolak unjuran vektor ini ke atas vektor sebelumnya untuk memastikan ortogonaliti.
Jika ia belum ternormal, normalkan ia. Dalam kes ini, vektor tersebut sudah ternormal, jadi
Kita kini mengunjurkan matriks A ke atas subruang dua vektor ini:
Kita masih menghadapi masalah menentukan nilai eigen matriks ini. Tetapi matriks ini sedikit lebih kecil daripada matriks penuh. Dalam masalah yang melibatkan matriks yang sangat besar, bekerja dengan subruang yang lebih kecil ini mungkin sangat menguntungkan.
Walaupun ini masih bukan anggaran yang baik, ia lebih baik daripada anggaran tertib sifar. Kita akan menjalankan ini untuk satu lagi iterasi, untuk memastikan prosesnya jelas. Namun, ini melemahkan tujuan kaedah, kerana kita akan mendiagonalisasikan matriks 3x3 dalam iterasi seterusnya, bermakna kita tidak menjimatkan masa atau kuasa pengkomputeran.
Dimensi :
Kita kini menjana vektor seterusnya dalam subruang kita melalui operasi dengan A pada vektor sebelumnya:
Sekarang kita tolak unjuran vektor ini ke atas kedua-dua vektor sebelumnya untuk memastikan ortogonaliti.
Jika ia belum ternormal, normalkan ia. Dalam kes ini, vektor tersebut sudah ternormal, jadi
Kita kini mengunjurkan matriks ke atas subruang vektor-vektor ini:
Kita kini menentukan nilai eigen:
Nilai eigen ini adalah tepat sama dengan nilai eigen matriks asal . Ini mesti berlaku, kerana kita telah mengembangkan subruang Krylov kita untuk merentangi seluruh ruang vektor matriks asal .
Dalam contoh ini, kaedah Krylov mungkin tidak kelihatan lebih mudah daripada diagonalisasi terus. Memang, seperti yang akan kita lihat dalam bahagian kemudian, kaedah Krylov hanya menguntungkan di atas dimensi matriks tertentu; ini bertujuan untuk membantu kita menyelesaikan masalah nilai eigen/vektor eigen matriks yang sangat besar.
Ini adalah satu-satunya contoh yang akan kita tunjukkan dengan cara "tangan", tetapi bahagian 2 di bawah menunjukkan contoh pengkomputeran.
Penjelasan istilah
Satu salah faham biasa ialah terdapat hanya satu subruang Krylov untuk satu masalah yang diberikan. Tetapi tentunya, kerana terdapat banyak vektor awal yang boleh dikenakan matriks kita, terdapat banyak subruang Krylov yang mungkin. Kita hanya akan menggunakan ungkapan "the Krylov subspace" untuk merujuk kepada subruang Krylov tertentu yang sudah ditentukan untuk contoh tertentu. Untuk pendekatan penyelesaian masalah umum kita akan merujuk kepada "a Krylov subspace". Penjelasan terakhir ialah adalah sah merujuk kepada "Krylov space". Seseorang sering melihatnya dipanggil "Krylov subspace" kerana penggunaannya dalam konteks mengunjurkan matriks dari ruang awal ke subruang. Seiring dengan konteks tersebut, kita kebanyakannya akan merujuknya sebagai subruang di sini.
Uji kefahaman anda
Baca soalan-soalan di bawah, fikirkan jawapan anda, kemudian klik segi tiga untuk mendedahkan setiap penyelesaian.
Terangkan kenapa (a) tidak berguna, dan (b) tidak mungkin untuk meluaskan dimensi subruang Krylov melebihi dimensi matriks yang diminati.
Jawapan:
(a) Kerana kita mengortogonalkan vektor semasa kita menghasilkannya, satu set vektor sedemikian akan membentuk asas lengkap, bermakna gabungan linear mereka boleh digunakan untuk mencipta sebarang vektor dalam ruang tersebut. (b) Proses pengortogonalan terdiri daripada menolak unjuran vektor baru ke atas semua vektor sebelumnya. Jika semua vektor sebelumnya merentangi ruang vektor penuh, maka menolak unjuran ke atas subruang penuh akan sentiasa menghasilkan vektor sifar.
Andaikan seorang rakan penyelidik sedang menunjukkan kaedah Krylov yang digunakan pada matriks mainan kecil untuk beberapa rakan sekerja. Rakan penyelidik ini merancang untuk menggunakan matriks dan vektor awal:
dan
Adakah ada yang salah dengan ini? Bagaimana anda menasihati rakan sekerja anda?
Jawapan:
Rakan sekerja anda telah secara tidak sengaja memilih vektor eigen sebagai vektor awalnya. Bertindak dengan matriks pada vektor awal hanya akan mengembalikan vektor yang sama, diskala oleh nilai eigen. Ini tidak akan menjana subruang yang meningkat dimensinya. Nasihatkan rakan sekerja anda untuk memilih vektor awal yang berbeza, memastikan ia bukan vektor eigen.
Terapkan kaedah Krylov pada matriks di bawah, pilih vektor awal baru yang sesuai. Tulis anggaran nilai eigen minimum pada tertib ke-0 dan ke-1 subruang Krylov anda.
Jawapan:
Terdapat banyak jawapan yang mungkin bergantung pada pilihan vektor awal. Kita akan memilih:
Untuk mendapatkan kita kenakan sekali pada , dan kemudian jadikan berortogonal dengan
Pada tertib ke-0, unjuran ke atas subruang Krylov kita ialah
Pada tertib ke-1, unjuran ke atas subruang Krylov ini ialah
Ini boleh dilakukan dengan tangan, tetapi paling mudah menggunakan numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
output:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
Anggaran nilai eigen minimum ialah -0.414.
1.2 Jenis-jenis kaedah Krylov
"Kaedah subruang Krylov" boleh merujuk kepada mana-mana daripada beberapa teknik iteratif yang digunakan untuk menyelesaikan sistem linear yang besar dan masalah nilai eigen. Apa yang mereka semua ada persamaan ialah mereka membina penyelesaian anggaran daripada subruang Krylov
di mana ialah tekaan awal (lihat Ref [5]). Mereka berbeza dalam cara mereka memilih anggaran terbaik daripada subruang ini, mengimbangi faktor-faktor seperti kadar konvergensi, penggunaan memori, dan kos pengkomputeran keseluruhan. Fokus pelajaran ini adalah memanfaatkan pengkomputeran kuantum dalam konteks kaedah subruang Krylov; perbincangan menyeluruh tentang kaedah-kaedah ini adalah di luar skopnya. Definisi ringkas di bawah adalah untuk konteks sahaja dan termasuk beberapa rujukan untuk menyelidiki kaedah-kaedah ini lebih lanjut.
Kaedah kecerunan konjugat (CG): Kaedah ini digunakan untuk menyelesaikan sistem linear simetri, positif definitif[6]. Ia meminimumkan norma-A ralat pada setiap iterasi, menjadikannya sangat berkesan untuk sistem yang timbul daripada PDE eliptik yang didiskretkan[7]. Kita akan menggunakan pendekatan ini dalam bahagian seterusnya untuk memotivasikan kenapa subruang Krylov akan menjadi subruang yang berkesan untuk mencari penyelesaian yang lebih baik kepada sistem linear.
Kaedah residual minimal teritlak (GMRES): Ini direka untuk menyelesaikan sistem linear bukan simetri umum. Ia meminimumkan norma residual ke atas ruang Krylov pada setiap iterasi, menjadikannya mantap tetapi berpotensi memerlukan memori yang besar untuk sistem besar[7].
Kaedah residual minimal (MINRES): Kaedah ini digunakan untuk menyelesaikan sistem linear tak tentu simetri. Ia serupa dengan GMRES tetapi memanfaatkan simetri matriks untuk mengurangkan kos pengkomputeran[8].
Pendekatan lain yang patut disebut termasuk kaedah pengortogonalan penuh (FOM), yang berkait rapat dengan kaedah Arnoldi untuk masalah nilai eigen, kaedah kecerunan bi-konjugat (BiCG), dan kaedah pengurangan dimensi teraruh (IDR).
1.3 Kenapa kaedah subruang Krylov berkesan
Di sini kita akan memotivasikan bahawa kaedah subruang Krylov haruslah menjadi cara yang cekap untuk menganggar nilai eigen matriks melalui penambahbaikan iteratif anggaran vektor eigen, melalui kanta penurunan tercerun. Kita akan berhujah bahawa diberikan tekaan awal keadaan tanah, ruang pembetulan berturutan pada tekaan awal yang menghasilkan konvergensi terpantas adalah subruang Krylov. Kita tidak sampai pada bukti ketat tingkah laku konvergensi.
Andaikan matriks yang kita minati adalah simetri dan positif definitif. Ini menjadikan hujah kita paling relevan dengan kaedah CG di atas. Kita tidak membuat andaian tentang kehampaan di sini; kita juga tidak mendakwa bahawa mesti Hermitian (yang diperlukan jika ia adalah Hamiltonian).
Kita biasanya ingin menyelesaikan masalah berbentuk
Seseorang mungkin membayangkan bahawa di mana adalah pemalar, seperti dalam masalah nilai eigen. Tetapi pernyataan masalah kita kekal lebih umum buat masa ini.
Kita mulakan dengan vektor yang merupakan penyelesaian anggaran. Walaupun terdapat persamaan antara tekaan ini dan dalam Bahagian 1.1, kita tidak memanfaatkannya di sini. Tekaan kita mempunyai ralat, yang kita panggil
Kita juga mendefinisikan residual
Di sini kita menggunakan huruf besar untuk membezakan residual daripada dimensi subruang Krylov kita .

Kita kini ingin membuat langkah pembetulan berbentuk
yang kita harap akan memperbaiki anggaran kita. Di sini ialah beberapa vektor yang belum ditentukan. Biarkan menjadi ralat selepas pembetulan dibuat. Maka

Kita berminat tentang bagaimana ralat kita berkelakuan apabila diubah suai oleh matriks kita. Jadi mari kita kira norma- ralat. Iaitu
di mana kita telah menggunakan simetri dan juga bahawa Di sini adalah pemalar yang bebas daripada . Seperti yang dinyatakan dalam Bahagian 1.2, norma- ralat bukan satu-satunya kuantiti yang mungkin kita pilih untuk diminimumkan, tetapi ia adalah pilihan yang baik. Kita ingin melihat bagaimana kuantiti ini berubah-ubah dengan pilihan kita untuk vektor pembetulan Jadi kita definisikan fungsi dengan menetapkan
hanyalah ralat sebagai fungsi pembetulan yang diukur dalam norma-. Oleh itu, kita ingin memilih supaya sekecil mungkin. Untuk tujuan ini, kita kira kecerunan . Menggunakan simetri kita ada
Kecerunan menghala ke arah pendakian tercerun, bermakna lawanannya memberikan kita arah di mana fungsi menurun paling banyak: arah penurunan tercerun. Pada tekaan awal , di mana , kita ada bahawa Oleh itu, fungsi menurun paling banyak ke arah residual Jadi pilihan awal kita akan paling menguntungkan dengan penambahan vektor untuk beberapa skalar .
Dalam langkah seterusnya, kita memilih sekali lagi vektor dan menambah nilainya pada anggaran semasa. Menggunakan hujah yang sama seperti sebelumnya kita memilih untuk beberapa skalar . Kita teruskan dengan cara ini, supaya iterasi ke- vektor kita ialah
Secara setara, kita ingin membina ruang dari mana kita memilih anggaran yang lebih baik dengan menambah , , dan seterusnya, secara tertib. Vektor anggaran ke- berada dalam
Sekarang, menggunakan hubungan bahawa
kita lihat bahawa
Iaitu, ruang yang kita bina yang paling cekap menganggar penyelesaian betul adalah tepat ruang yang dibina oleh operasi berturutan matriks pada Subruang Krylov ialah ruang yang dicakupi oleh vektor-vektor arah penurunan tercerun berturutan.
Akhirnya kita menegaskan semula bahawa kita tidak membuat sebarang tuntutan berangka tentang penskalaan pendekatan ini, mahupun kita telah membincangkan manfaat perbandingan untuk matriks jarang. Ini hanya bertujuan untuk memotivasikan penggunaan kaedah subruang Krylov, dan menambah beberapa rasa intuitif untuknya. Kita kini akan meneroka tingkah laku kaedah-kaedah ini secara berangka.
Uji kefahaman anda
Baca soalan di bawah, fikirkan jawapan anda, kemudian klik segi tiga untuk mendedahkan penyelesaiannya.
Dalam aliran kerja di atas, kita mencadangkan meminimumkan norma- ralat. Kuantiti lain apakah yang mungkin dipertimbangkan untuk diminimumkan dalam mencari keadaan tanah dan nilai eigennya?
Jawapan:
Seseorang boleh membayangkan menggunakan vektor residual sebagai ganti norma- ralat. Mungkin ada kes di mana mempertimbangkan vektor ralat itu sendiri berguna.
2. Kaedah Krylov dalam pengkomputeran klasik
Dalam bahagian ini kita melaksanakan iterasi Arnoldi secara pengkomputeran supaya kita boleh memanfaatkan subruang Krylov dalam menyelesaikan masalah nilai eigen. Kita akan menerapkannya pertama pada contoh berskala kecil, kemudian mengkaji bagaimana masa pengkomputeran berskala dengan dimensi matriks yang diminati. Idea utama di sini ialah penjanaan vektor yang merentangi ruang Krylov akan menjadi penyumbang besar kepada jumlah masa pengkomputeran yang diperlukan. Memori yang diperlukan akan berbeza antara kaedah Krylov yang spesifik. Tetapi kekangan memori boleh mengehadkan penggunaan kaedah Krylov tradisional.
2.1 Contoh berskala kecil yang mudah
Dalam proses mencipta subruang Krylov, kita perlu mengortogonalkan vektor dalam subruang kita. Mari kita definisikan fungsi yang mengambil vektor yang telah ditetapkan daripada subruang kita vknown (tidak dianggap ternormal) dan vektor calon untuk ditambah ke subruang kita vnext dan jadikan vnext berortogonal dengan vknown dan ternormal. Mari kita juga definisikan fungsi yang melalui proses ini untuk semua vektor yang telah ditetapkan dalam subruang Krylov kita untuk memastikan set ortonormal sepenuhnya.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
Sekarang mari kita definisikan fungsi yang membina subruang Krylov yang semakin besar secara iteratif, sehingga ruang vektor Krylov merentangi ruang penuh matriks asal. Ini akan membolehkan kita melihat seberapa baik nilai eigen yang diperoleh menggunakan kaedah subruang Krylov kita sepadan dengan nilai tepat, sebagai fungsi dimensi subruang Krylov. Yang penting, fungsi kita krylov_full_build mengembalikan vektor Krylov, Hamiltonian yang diunjurkan, nilai eigen, dan masa yang diperlukan.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
Kita akan menguji ini pada matriks yang masih agak kecil, tetapi lebih besar daripada yang mungkin kita ingin buat dengan tangan.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
Kita boleh menyemak fungsi kita dengan memastikan bahawa pada langkah terakhir (apabila ruang Krylov adalah ruang vektor penuh matriks asal) nilai eigen daripada kaedah Krylov sepadan tepat dengan diagonalisasi berangka tepat:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
Itu berjaya. Tentunya, yang paling penting ialah seberapa baik anggaran kita sebagai fungsi dimensi subruang Krylov kita. Kerana kita sering berpusat pada mencari keadaan tanah dan nilai eigen minimum lain (dan atas sebab-sebab lebih aljabar yang dijelaskan di bawah), mari kita lihat anggaran nilai eigen terendah kita sebagai fungsi dimensi subruang Krylov. Iaitu
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
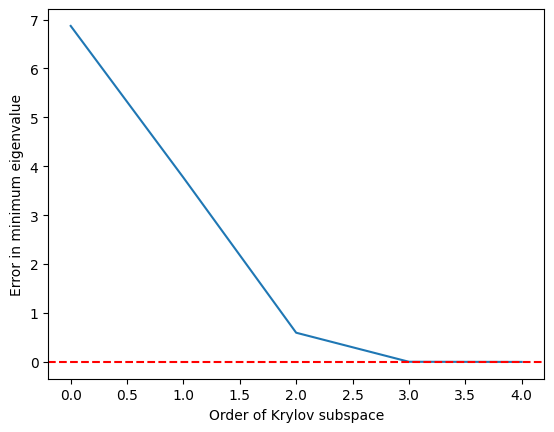
Kita lihat bahawa nilai eigen minimum dicapai dengan tepat setelah subruang Krylov berkembang kepada dan sempurna pada
2.2 Penskalaan masa dengan dimensi matriks
Mari kita yakinkan diri kita bahawa kaedah Krylov boleh lebih menguntungkan daripada penyelesai nilai eigen berangka tepat dengan cara berikut:
- Bina matriks rawak (bukan jarang, bukan aplikasi ideal untuk KQD)
- Tentukan nilai eigen menggunakan dua kaedah: secara langsung menggunakan NumPy dan menggunakan subruang Krylov.
- Kita pilih titik potong seberapa tepat nilai eigen kita mesti, sebelum kita menerima anggaran Krylov.
- Bandingkan masa dinding yang diperlukan untuk diselesaikan dengan dua cara ini.
Peringatan: Seperti yang akan kita bincangkan secara terperinci di bawah, diagonalisasi krylov kuantum paling baik diterapkan pada operator yang representasi matriksnya adalah jarang dan/atau boleh ditulis menggunakan bilangan kecil kumpulan operator Pauli yang berkomut. Matriks rawak yang kita gunakan di sini tidak memenuhi penerangan tersebut. Ini hanya berguna untuk mengkaji skala di mana kaedah Krylov klasik mungkin berguna. Kedua, dalam menggunakan kaedah Krylov kita akan mengira nilai eigen menggunakan banyak subruang Krylov berbeza saiznya. Kita akan melaporkan masa yang diperlukan untuk subruang Krylov berdimensi minimum yang mencapai ketepatan yang diperlukan untuk nilai eigen keadaan tanah. Sekali lagi, ini agak berbeza daripada menyelesaikan masalah yang tidak boleh diselesaikan untuk penyelesai nilai eigen tepat, kerana kita menggunakan penyelesaian tepat untuk menilai dimensi yang diperlukan.
Kita mulakan dengan menjana set matriks rawak kita.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
Kita kini mendiagonalisasikan setiap matriks secara langsung, menggunakan numpy. Kita mengira masa yang diperlukan untuk diagonalisasi untuk perbandingan kemudian.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
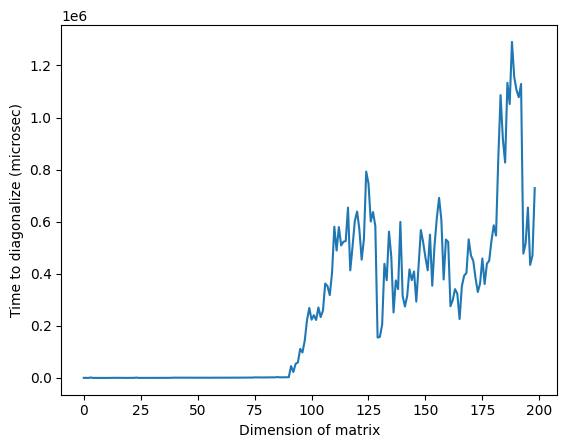
Perhatikan bahawa dalam imej di atas, masa yang luar biasa tinggi sekitar dimensi 125 mungkin disebabkan oleh sifat rawak matriks atau pelaksanaan pada pemproses klasik yang digunakan, tetapi ia tidak boleh direproduksi. Menjalankan semula kod akan menghasilkan profil berbeza dengan puncak anomali yang berbeza.
Sekarang untuk setiap matriks kita akan membina subruang Krylov dan mengira nilai eigen secara berperingkat. Pada setiap langkah, kita akan memeriksa sama ada nilai eigen terendah telah diperoleh dalam ralat mutlak yang ditentukan. Subruang yang pertama kali memberikan kita nilai eigen dalam ralat yang ditentukan ialah subruang untuk masa pengkomputeran yang akan kita rekodkan. Melaksanakan sel ini mungkin mengambil beberapa minit, bergantung pada kelajuan pemproses. Jangan ragu untuk melangkau penilaian atau mengurangkan dimensi maksimum matriks yang didiagonalisasikan. Melihat keputusan yang telah dikira sudah mencukupi.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
Mari kita plot masa yang kita peroleh untuk dua kaedah ini untuk perbandingan:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

Ini adalah masa sebenar yang diperlukan, tetapi untuk tujuan perbincangan, mari kita ratakan keluk-keluk ini dengan mengambil purata beberapa titik/dimensi matriks bersebelahan. Ini dilakukan di bawah:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

Perhatikan bahawa masa yang diperlukan untuk membina subruang Krylov pada awalnya melebihi masa yang diperlukan untuk diagonalisasi penuh numpy. Tetapi apabila saiz matriks berkembang, kaedah Krylov menjadi lebih menguntungkan. Ini benar walaupun kita menurunkan ralat yang boleh diterima, tetapi kelebihannya bermula pada saiz matriks yang lebih besar. Ini patut diteliti dengan lebih lanjut.
Kerumitan masa diagonalisasi berangka ialah (dengan beberapa variasi antara algoritma). Kerumitan masa menjana asas ortonormal vektor juga ialah . Jadi kelebihan kaedah Krylov bukan berkaitan dengan penggunaan beberapa asas ortonormal, tetapi dengan penggunaan asas ortonormal tertentu yang secara berkesan memilih nilai eigen yang diminati. Kita sudah melihat ini daripada lakaran bukti dalam bahagian pertama pelajaran ini, dan ini adalah kritikal untuk jaminan konvergensi dalam kaedah Krylov. Mari kita semak kemajuan kita setakat ini:
- Untuk matriks yang sangat besar, kaedah subruang Krylov mungkin menghasilkan nilai eigen anggaran dalam toleransi yang diperlukan lebih cepat daripada algoritma diagonalisasi tradisional.
- Untuk matriks yang sangat besar sedemikian, penjanaan subruang Krylov adalah bahagian yang paling memakan masa dalam kaedah subruang Krylov.
- Oleh itu cara yang cekap untuk menjana subruang Krylov akan sangat bernilai. Di sinilah akhirnya komputer kuantum muncul.
Uji kefahaman anda
Baca soalan di bawah, fikirkan jawapan anda, kemudian klik segi tiga untuk mendedahkan penyelesaiannya.
Rujuk plot licin masa diagonalisasi berbanding dimensi matriks di atas.
(a) Pada dimensi matriks yang lebih kurang berapa kaedah Krylov menjadi lebih cepat, menurut plot ini?
(b) Aspek pengiraan mana yang boleh mengubah dimensi di mana kaedah Krylov menjadi lebih cepat?
Jawapan:
(a) Jawapan mungkin berbeza jika kamu menjalankan semula pengiraan, tetapi kaedah Krylov menjadi lebih cepat pada dimensi kira-kira 80-85. (b) Terdapat banyak jawapan yang mungkin. Beberapa faktor penting ialah ketepatan yang kita perlukan dan kehampaan matriks yang didiagonalisasikan.
3. Krylov melalui evolusi masa
Semua yang telah kita huraikan setakat ini boleh dilakukan secara klasik. Jadi bagaimana dan bila kita akan menggunakan komputer kuantum? Untuk matriks yang sangat besar, kaedah Krylov boleh memerlukan masa pengkomputeran yang lama dan jumlah memori yang besar. Masa yang diperlukan untuk operasi matriks pada berskala seperti dalam kes terburuk. Malah mendarabkan matriks jarang pada vektor (kes biasa untuk penyelesai Krylov klasik) mempunyai kerumitan masa yang berskala seperti . Ini dilakukan untuk setiap vektor yang kita inginkan dalam subruang kita. Dimensi subruang biasanya bukan pecahan besar daripada , dan sering berskala seperti . Jadi menjana semua vektor berskala seperti dalam kes terburuk. Walaupun terdapat langkah-langkah lain seperti pengortogonalan, ini adalah penskalaan dominan untuk diingati.
Pengkomputeran kuantum membolehkan kita mengubah sifat masalah mana yang menentukan penskalaan masa dan sumber yang diperlukan. Daripada kebergantungan pada saiz matriks di setiap bahagian, kita akan melihat perkara seperti bilangan shots dan bilangan sebutan Pauli yang tidak berkomut yang membentuk Hamiltonian. Mari kita terokai bagaimana ini berfungsi.
3.1 Evolusi masa
Ingat bahawa operator yang mengevolusi masa keadaan kuantum ialah (dan adalah sangat biasa, terutamanya dalam pengkomputeran kuantum, untuk menggugurkan daripada notasi). Satu cara untuk memahami dan bahkan merealisasikan fungsi eksponen operator sedemikian ialah melihat pengembangan siri Taylornya. Perhatikan bahawa operasi ini yang bertindak ke atas beberapa vektor awal menghasilkan jumlah sebutan dengan kuasa yang meningkat yang digunakan pada keadaan awal. Nampaknya kita boleh membuat subruang Krylov kita dengan mengevolusi masa keadaan tekaan awal kita!
Peringatannya ialah dalam merealisasikan evolusi masa pada komputer kuantum sebenar. Banyak sebutan dalam Hamiltonian tidak akan berkomut antara satu sama lain. Jadi walaupun beberapa operator eksponen mudah seperti sepadan dengan litar mudah, Hamiltonian am tidak. Dan kerana mereka mengandungi sebutan yang tidak berkomut, kita tidak boleh hanya menguraikan eksponen kepada produk yang mudah, seperti yang boleh kita lakukan dengan nombor.
Jadi ini bukan perkara mudah, tetapi ini adalah proses yang telah dikaji dengan mendalam dalam pengkomputeran kuantum. Kita melaksanakan evolusi masa pada komputer kuantum menggunakan proses yang dipanggil trotterisasi, yang dalam dirinya sendiri adalah subjek yang kaya[10]. Tetapi pada peringkat yang sangat tinggi, dengan memecahkan evolusi masa kepada langkah-langkah yang sangat kecil, katakan langkah saiz , kita mengehadkan kesan ketidak-komutatifan sebutan.
di mana .
Mari kita panggil subruang Krylov berdarjah r yang kita jana dalam konteks klasik menggunakan kuasa H secara langsung sebagai "subruang Krylov kuasa".
Sekarang kita jana ruang yang serupa menggunakan operator evolusi masa unitari ; kita akan menyebutnya sebagai "ruang Krylov unitari" . Subruang Krylov kuasa yang kita gunakan secara klasik tidak boleh dijana secara langsung pada komputer kuantum kerana bukan operator unitari. Menggunakan subruang Krylov unitari boleh ditunjukkan memberikan jaminan konvergensi yang serupa dengan subruang Krylov kuasa, iaitu ralat keadaan tanah menumpu dengan cekap selagi keadaan awal mempunyai pertindihan dengan keadaan tanah sebenar yang tidak lenyap secara eksponen, dan selagi terdapat jurang yang mencukupi antara nilai eigen. Lihat Ref [1] untuk perbincangan konvergensi yang lebih tepat.
Di sini, kuasa menjadi langkah masa yang berbeza (kuasa ke- daripada ialah melangkah ke hadapan sebanyak masa ). Kita boleh melabel elemen subruang yang dievolusi masa selama jumlah masa sebagai .
Kita boleh mengunjurkan Hamiltonian H kita ke atas subruang Krylov unitari, . Dengan kata lain, kita mengira setiap elemen matriks dalam asas . Kita akan merujuk matriks yang diunjurkan ini sebagai .
3.2 Cara melaksanakan pada komputer kuantum
Elemen matriks diberikan oleh nilai jangkaan , yang boleh dianggar menggunakan komputer kuantum. Ingat bahawa boleh ditulis sebagai jumlah operator Pauli pada qubit yang berbeza, dan tidak semua operator Pauli boleh diukur secara serentak. Kita boleh mengisih sebutan Pauli ke dalam kumpulan sebutan berkomut, dan mengukur semuanya sekaligus. Tetapi kita mungkin memerlukan banyak kumpulan sedemikian untuk merangkumi semua sebutan. Jadi bilangan kumpulan berkomut berbeza di mana sebutan boleh dipartisi, menjadi penting.
Di sini ialah rentetan Pauli berbentuk atau satu set rentetan Pauli sedemikian yang berkomut antara satu sama lain. Memandangkan kita boleh menulis sebagai jumlah operator yang boleh diukur sedemikian, ungkapan berikut untuk elemen matriks boleh direalisasikan menggunakan primitif Estimator Qiskit Runtime.
Di mana adalah vektor ruang Krylov unitari dan adalah gandaan langkah masa yang dipilih. Pada komputer kuantum, pengiraan setiap elemen matriks boleh dilakukan dengan sebarang algoritma yang membolehkan kita mendapatkan pertindihan antara keadaan kuantum. Dalam pelajaran ini kita akan fokus pada ujian Hadamard. Memandangkan mempunyai dimensi , Hamiltonian yang diunjurkan ke dalam subruang akan mempunyai dimensi . Dengan yang cukup kecil (umumnya adalah mencukupi untuk mendapatkan konvergensi anggaran nilai eigen) kita kemudiannya boleh mendiagonalisasikan Hamiltonian yang diunjurkan dengan mudah secara klasik. Namun, kita tidak boleh mendiagonalisasikan secara langsung kerana ketidak-ortogonalan vektor ruang Krylov. Kita perlu mengukur pertindihan mereka dan membina matriks
Ini membolehkan kita menyelesaikan masalah nilai eigen dalam ruang bukan ortogonal (juga dipanggil masalah nilai eigen teritlak)
Seseorang kemudiannya boleh mendapatkan anggaran nilai eigen dan keadaan eigen dengan melihat penyelesaian masalah nilai eigen teritlak ini. Sebagai contoh, anggaran tenaga keadaan tanah diperoleh dengan mengambil nilai eigen terkecil dan keadaan tanah daripada vektor eigen yang sepadan . Pekali dalam menentukan sumbangan vektor berbeza yang merentangi .
Masalah nilai eigen teritlak
Kenapa kita tidak boleh hanya mendiagonalisasikan ? Kerana mengandungi maklumat tentang geometri asas Krylov (yang bukan ortogonal kecuali dalam kes yang sangat istimewa), sahaja tidak menggambarkan unjuran Hamiltonian penuh, jadi nilai eigennya tidak mempunyai hubungan tertentu dengan nilai eigen Hamiltonian penuh -- ia boleh menjadi sebarang nilai rawak. Menyelesaikan masalah nilai eigen teritlak diperlukan untuk mendapatkan nilai eigen anggaran dan vektor eigen yang sepadan dengan unjuran Hamiltonian penuh ke dalam ruang Krylov.
Rajah menunjukkan perwakilan litar ujian Hadamard yang dimodifikasi, kaedah yang digunakan untuk mengira pertindihan antara keadaan kuantum yang berbeza. Untuk setiap elemen matriks , ujian Hadamard antara keadaan , dijalankan. Ini disorot dalam rajah oleh skema warna untuk elemen matriks dan operasi , yang sepadan. Oleh itu, satu set ujian Hadamard untuk semua kombinasi yang mungkin dari vektor ruang Krylov diperlukan untuk mengira semua elemen matriks Hamiltonian yang diunjurkan . Wayar atas dalam litar ujian Hadamard ialah qubit ancilla yang diukur sama ada dalam asas X atau Y, nilai jangkaannya menentukan nilai pertindihan antara keadaan. Wayar bawah mewakili semua qubit Hamiltonian sistem. Operasi menyediakan qubit sistem dalam keadaan yang dikawal oleh keadaan qubit ancilla (begitu juga untuk ) dan operasi mewakili penguraian Pauli Hamiltonian sistem . Pelaksanaan ini pada komputer kuantum ditunjukkan dengan lebih terperinci di bawah.
4. Diagonalisasi krylov kuantum pada komputer kuantum
Kita kini akan melaksanakan diagonalisasi krylov kuantum pada komputer kuantum sebenar. Mari kita mulakan dengan mengimport beberapa pakej yang berguna.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
Kita definisikan fungsi di bawah untuk menyelesaikan masalah nilai eigen teritlak yang baru kita jelaskan.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
Sekurang-kurangnya dalam penanda aras awal, adalah berguna untuk mengetahui penyelesaian klasik tepat untuk memeriksa tingkah laku konvergensi. Fungsi di bawah mengira tenaga keadaan tanah Hamiltonian, menggunakan Hamiltonian dan bilangan qubit sebagai argumen.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 Langkah 1: Petakan masalah kepada litar kuantum dan operator
Sekarang kita akan mendefinisikan Hamiltonian. Ini berbeza daripada fungsi di atas dalam bahawa fungsi di atas mengambil Hamiltonian sebagai argumen dan hanya mengembalikan keadaan tanah, dan ia melakukannya secara klasik. Hamiltonian yang kita definisikan di sini menentukan aras tenaga semua keadaan eigen tenaga, dan Hamiltonian ini boleh dibina menggunakan operator Pauli dan dilaksanakan pada komputer kuantum.
Kita memilih Hamiltonian yang sepadan dengan rantaian spin yang boleh mempunyai sebarang orientasi dalam ruang, dipanggil "rantaian Heisenberg". Kita andaikan bahawa spin ke- boleh dipengaruhi oleh jirannya yang terdekat (spin ke- dan ) tetapi bukan oleh jiran yang lebih jauh. Kita juga membenarkan kemungkinan bahawa interaksi antara spin adalah berbeza apabila spin menghala ke arah paksi yang berbeza. Asimetri ini kadang-kadang timbul, sebagai contoh, disebabkan struktur kekisi kristal di mana spin tertanam.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
Kod di bawah mengehadkan Hamiltonian kepada keadaan zarah tunggal, dan menggunakan norma spektrum untuk menetapkan saiz langkah masa yang baik. Kita memilih nilai dt (berdasarkan had atas norma Hamiltonian) secara heuristik. Ref [9] menunjukkan bahawa langkah masa yang mencukupi ialah , dan adalah lebih baik sehingga satu titik untuk memperkirakan nilai ini terlalu rendah daripada terlalu tinggi, kerana menganggarnya terlalu tinggi boleh membenarkan sumbangan dari keadaan tenaga tinggi merosakkan keadaan optimum dalam ruang Krylov. Sebaliknya, memilih yang terlalu kecil membawa kepada pengkondisian subruang Krylov yang lebih buruk, kerana vektor asas Krylov kurang berbeza dari langkah masa ke langkah masa.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
Mari kita tentukan dimensi Krylov maksimum yang ingin kita gunakan, walaupun kita akan memeriksa konvergensi pada dimensi yang lebih kecil. Kita juga menentukan bilangan langkah Trotter yang akan digunakan dalam evolusi masa. Untuk tujuan pelajaran ini, kita akan memilih dimensi Krylov yang kecil iaitu hanya 5. Ini agak terhad dalam konteks aplikasi realistik, tetapi ia mencukupi untuk contoh ini. Kita akan meneroka kaedah dalam pelajaran kemudian yang membolehkan kita menskalakan dan mengunjurkan Hamiltonian kita ke atas subruang yang lebih besar.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
Penyediaan keadaan
Pilih keadaan rujukan yang mempunyai beberapa pertindihan dengan keadaan tanah. Untuk Hamiltonian ini, kita menggunakan keadaan dengan rangsangan di qubit tengah sebagai keadaan rujukan kita.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

Evolusi masa
Kita boleh merealisasikan operator evolusi masa yang dijana oleh Hamiltonian yang diberikan: melalui penghampiran Lie-Trotter. Untuk kesederhanaan kita menggunakan PauliEvolutionGate terbina dalam litar evolusi masa. Sintaks umum untuk ini adalah seperti berikut.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
Kita akan menggunakan versi ini di bawah dalam ujian Hadamard, tetapi melangkah ke hadapan untuk masa .
Ujian Hadamard
Ingat bahawa kita ingin mengira elemen matriks dan matriks Gram menggunakan ujian Hadamard. Mari kita semak bagaimana ini berfungsi dalam konteks ini, fokus pertama pada pembinaan Proses keseluruhan digambarkan secara grafik di bawah. Lapisan blok penyediaan keadaan berwarna berfungsi sebagai peringatan bahawa proses ini dijalankan untuk semua kombinasi dan dalam subruang kita.
Keadaan sistem pada langkah-langkah yang ditunjukkan ialah:
Di sini ialah sebutan Pauli dalam penguraian Hamiltonian (perhatikan bahawa ia tidak boleh menjadi gabungan linear beberapa sebutan Pauli berkomut kerana itu tidak akan unitari -- pengelompokan adalah mungkin menggunakan binaan berbeza yang akan kita tunjukkan kemudian) , ialah operasi terkawal yang menyediakan , vektor ruang Krylov unitari, dengan . Menggunakan pengukuran dan pada litar ini mengira bahagian nyata dan khayalan masing-masing elemen matriks yang kita perlukan.
Bermula dari Langkah 4 di atas, kenakan get Hadamard pada qubit sifar.
Kemudian ukur sama ada atau .
Daripada identiti . Begitu juga, mengukur menghasilkan
Menambah langkah-langkah ini pada evolusi masa yang kita sediakan sebelumnya kita tulis yang berikut.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

Kita sudah memberi amaran tentang kedalaman yang terlibat dalam litar Trotter. Melakukan ujian Hadamard dalam keadaan ini boleh menghasilkan litar yang lebih dalam, terutamanya setelah kita mengurai ke gate asas. Ini akan meningkat lagi jika kita mengambil kira topologi peranti. Jadi sebelum menggunakan sebarang masa pada komputer kuantum, adalah idea yang baik untuk memeriksa kedalaman 2-qubit litar kita.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
Litar sedalam ini tidak boleh menghasilkan keputusan yang berguna pada komputer kuantum moden. Jika kita ingin membina dan kita memerlukan cara yang lebih baik. Inilah sebabnya ujian Hadamard yang cekap diperkenalkan di bawah.
4. 2 Langkah 2. Optimumkan litar dan operator untuk perkakasan sasaran
Ujian Hadamard yang cekap
Kita boleh mengoptimumkan litar yang dalam untuk ujian Hadamard yang kita telah peroleh dengan memperkenalkan beberapa penghampiran dan bergantung pada beberapa andaian tentang Hamiltonian model. Sebagai contoh, pertimbangkan litar berikut untuk ujian Hadamard:
Andaikan kita boleh mengira secara klasik , nilai eigen di bawah Hamiltonian . Ini dipenuhi apabila Hamiltonian memelihara simetri U(1). Walaupun ini mungkin kelihatan seperti andaian yang kuat, terdapat banyak kes di mana adalah selamat untuk mengandaikan bahawa terdapat keadaan vakum (dalam kes ini ia memetakan kepada keadaan ) yang tidak terpengaruh oleh tindakan Hamiltonian. Ini benar contohnya untuk Hamiltonian kimia yang menggambarkan molekul stabil (di mana bilangan elektron terpelihara). Memandangkan gate , menyediakan keadaan rujukan yang dikehendaki , sebagai contoh, untuk menyediakan keadaan HF bagi kimia akan menjadi produk NOT qubit tunggal, jadi terkawal hanyalah produk CNOT. Kemudian litar di atas melaksanakan keadaan berikut sebelum pengukuran:
di mana kita telah menggunakan anjakan fasa yang boleh disimulasikan secara klasik dari langkah 2 ke 3. Oleh itu nilai jangkaan adalah
Dengan menggunakan andaian-andaian ini kita dapat menulis nilai jangkaan operator yang diminati dengan lebih sedikit operasi terkawal. Malah, kita hanya perlu melaksanakan penyediaan keadaan terkawal dan bukan evolusi masa terkawal. Menyusun semula pengiraan kita seperti di atas akan membolehkan kita sangat mengurangkan kedalaman litar yang terhasil.
Perhatikan bahawa sebagai bonus, kerana operator Pauli kini muncul sebagai pengukuran di hujung litar dan bukan sebagai gate terkawal di tengah, ia boleh diukur bersama operator Pauli berkomut yang lain seperti dalam penguraian yang diberikan di atas.
Uraikan operator evolusi masa dengan penguraian Trotter
Daripada melaksanakan operator evolusi masa dengan tepat kita boleh menggunakan penguraian Trotter untuk melaksanakan penghampiran operator tersebut. Mengulangi beberapa kali penguraian Trotter tertib tertentu memberikan kita pengurangan ralat yang lebih jauh yang diperkenalkan daripada penghampiran. Dalam langkah berikut, kita secara langsung membina pelaksanaan Trotter dengan cara yang paling cekap untuk graf interaksi Hamiltonian yang kita pertimbangkan (interaksi jiran terdekat sahaja). Dalam praktiknya kita menyisipkan putaran Pauli , , dengan sudut berparameter yang sepadan dengan pelaksanaan anggaran . Memandangkan perbezaan dalam definisi putaran Pauli dan evolusi masa yang kita cuba laksanakan, kita perlu menggunakan parameter untuk mencapai evolusi masa . Tambahan pula, kita membalikkan tertib operasi untuk bilangan langkah Trotter yang ganjil, yang secara fungsional setara tetapi membolehkan mensintesis operasi bersebelahan dalam satu unitari . Ini memberikan litar yang jauh lebih cetek daripada yang diperoleh menggunakan fungsi generik PauliEvolutionGate().
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
Kita menyediakan keadaan awal sekali lagi untuk ujian Hadamard yang cekap ini.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

Litar templat untuk mengira elemen matriks dan melalui ujian Hadamard
Satu-satunya perbezaan antara litar yang digunakan dalam ujian Hadamard ialah fasa dalam operator evolusi masa dan boleh diukur. Oleh itu kita boleh menyediakan litar templat yang mewakili litar generik untuk ujian Hadamard, dengan ruang tempat untuk gate yang bergantung pada operator evolusi masa.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
Kedalaman ini berkurang dengan ketara berbanding ujian Hadamard asal. Kedalaman ini boleh diurus pada komputer kuantum moden, walaupun masih agak tinggi. Kita perlu menggunakan mitigasi ralat mutakhir untuk mendapatkan keputusan yang berguna.
Pilih Backend untuk menjalankan pengiraan Krylov kuantum kita, supaya kita boleh mentranspil litar kita untuk dijalankan pada komputer kuantum tersebut.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
Kita kini mentranspil litar dan operator kita.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

Setelah pengoptimuman, kedalaman 2-qubit yang ditranspil kita dikurangkan lagi.
4.3 Langkah 3. Laksanakan menggunakan primitif Qiskit Runtime
Kita kini mencipta PUB untuk pelaksanaan dengan Estimator.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
Litar untuk boleh dikira secara klasik. Kita lakukan ini sebelum beralih ke kes menggunakan komputer kuantum.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
Walaupun kita dapat mengurangkan kedalaman gate kita dengan peringkat magnitud menggunakan ujian Hadamard yang cekap, kedalaman masih mencukupi untuk memerlukan mitigasi ralat mutakhir. Di bawah, kita menentukan atribut mitigasi yang digunakan. Semua kaedah yang digunakan adalah penting, tetapi patut disebut secara khusus penguatan ralat kebarangkalian (PEA). Teknik yang berkuasa ini disertai dengan banyak overhed kuantum. Pengiraan yang dilakukan di sini boleh mengambil masa 20 minit atau lebih untuk dijalankan pada komputer kuantum sebenar. Kamu mungkin ingin bermain dengan parameter di bawah untuk meningkatkan atau mengurangkan ketepatan dan overhed yang bersamaan. Tetapan lalai di bawah menghasilkan keputusan kesetiaan tinggi.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
Akhirnya, kita melaksanakan litar untuk dan dengan Estimator.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 Langkah 4. Pasca-proses dan analisis keputusan
Apa yang kita peroleh daripada komputer kuantum ialah elemen matriks individu dan kumpulan Pauli berkomut yang membentuk elemen matriks . Sebutan-sebutan ini mesti digabungkan untuk memulihkan matriks kita, supaya kita boleh menyelesaikan masalah nilai eigen teritlak.
# Store the outputs as 'results'.
results = job.result()[0]
Kira Hamiltonian Berkesan dan matriks Pertindihan
Pertama kira fasa yang terkumpul oleh keadaan semasa evolusi masa yang tidak dikawal
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
Setelah kita mendapat keputusan pelaksanaan litar kita boleh memproses data untuk mengira elemen matriks
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
Dan elemen matriks
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
Akhirnya, kita boleh menyelesaikan masalah nilai eigen teritlak untuk :
dan mendapat anggaran tenaga keadaan tanah
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
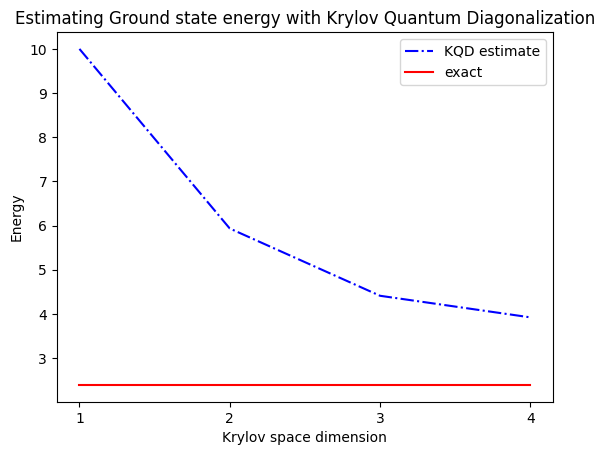
print("The estimated ground state energy is: ", gnd_en_circ_est)
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
Untuk sektor zarah tunggal, kita boleh mengira tenaga keadaan tanah sektor ini secara cekap secara klasik
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. Perbincangan dan perluasan
Untuk ringkasan, kita bermula dengan keadaan rujukan, kemudian mengevolusinya untuk tempoh masa yang berbeza untuk menjana subruang Krylov unitari. Kita mengunjurkan Hamiltonian kita ke atas subruang tersebut. Kita juga menganggar pertindihan vektor subruang. Akhirnya kita menyelesaikan masalah nilai eigen teritlak berdimensi lebih rendah secara klasik.
Mari kita bandingkan apa yang menentukan kos pengkomputeran menggunakan teknik Krylov secara klasik dan kuantum. Tiada analogi yang sempurna antara pendekatan klasik dan kuantum untuk semua langkah. Jadual ini mengumpulkan beberapa penskalaan langkah-langkah berbeza untuk pertimbangan.
Ingat bahawa Hamiltonian umumnya mempunyai sebutan yang tidak boleh diukur secara serentak (kerana ia tidak berkomut antara satu sama lain). Kita mengisih sebutan dalam Hamiltonian ke dalam kumpulan operator Pauli berkomut yang boleh semuanya diukur serentak, dan kita mungkin memerlukan banyak kumpulan sedemikian untuk merangkumi semua sebutan yang tidak berkomut antara satu sama lain. Untuk membina pada komputer kuantum memerlukan pengukuran berasingan untuk setiap kumpulan rentetan Pauli berkomut dalam Hamiltonian, dan setiap satunya memerlukan banyak shots. Kita mesti melakukan ini untuk elemen matriks berbeza, sepadan dengan kombinasi faktor evolusi masa yang berbeza. Kadang-kadang terdapat cara untuk mengurangkan ini, tetapi dalam rawatan kasar ini, masa yang diperlukan untuk ini berskala seperti Elemen mesti dianggar, yang berskala seperti . Akhirnya, menyelesaikan masalah nilai eigen teritlak dalam ruang yang diunjurkan secara klasik mengambil
Kita melihat bahawa diagonalisasi krylov kuantum mungkin berguna dalam kes di mana bilangan kumpulan Pauli berkomut dalam Hamiltonian adalah agak kecil. Kebergantungan penskalaan ini mencadangkan beberapa aplikasi di mana kaedah Krylov boleh berguna, dan yang lain di mana ia mungkin tidak. Beberapa Hamiltonian mempunyai kerumitan yang tinggi apabila dipetakan ke qubit, melibatkan banyak rentetan Pauli yang tidak berkomut yang tidak mudah dipartisi ke dalam beberapa kumpulan berkomut. Ini sering berlaku untuk masalah kimia kuantum, sebagai contoh. Kerumitan ini membentangkan dua cabaran utama untuk komputer kuantum jangka dekat:
- Anggaran setiap elemen menjadi mahal dari segi pengkomputeran disebabkan bilangan sebutan yang besar.
- Litar Trotter yang diperlukan menjadi terlalu dalam.
Kedua-dua perkara di atas akan kurang bermasalah apabila komputer kuantum mencapai toleransi ralat, tetapi ia mesti dipertimbangkan dalam jangka dekat. Malah sistem dengan pemetaan yang lebih "mudah" daripada yang ada dalam kimia kuantum mungkin mengalami halangan yang sama, jika Hamiltonian mempunyai terlalu banyak sebutan yang tidak berkomut. Kaedah Krylov paling berguna di mana Hamiltonian boleh dipartisi ke dalam beberapa kumpulan Pauli berkomut yang agak sedikit, dan di mana mudah dilaksanakan dalam litar Trotter. Kedua-dua syarat ini dipenuhi, sebagai contoh, untuk banyak model kekisi yang diminati dalam fizik. KQD sangat berguna jika sangat sedikit yang diketahui tentang keadaan tanah. Ini berpunca daripada jaminan konvergensi yang sedia ada dan kebolehgunaannya dalam senario di mana kaedah alternatif tidak boleh dilaksanakan kerana pengetahuan keadaan tanah yang tidak mencukupi.
Walaupun KQD adalah alat yang berkuasa, aspek-aspek protokol yang memakan masa, terutamanya anggaran setiap elemen Hamiltonian yang diunjurkan dan pertindihan keadaan Krylov, mewakili peluang untuk penambahbaikan. Pendekatan alternatif melibatkan memanfaatkan kaedah Krylov bersama kaedah berasaskan pensampelan, yang menjadi subjek pelajaran seterusnya.
6. Lampiran
Lampiran I: Subruang Krylov daripada evolusi masa nyata
Ruang Krylov unitari ditakrifkan sebagai
untuk beberapa langkah masa yang akan kita tentukan kemudian. Buat sementara waktu andaikan adalah genap: kemudian definisikan . Perhatikan bahawa apabila kita mengunjurkan Hamiltonian ke dalam ruang Krylov di atas, ia tidak dapat dibezakan daripada ruang Krylov
iaitu, di mana semua evolusi masa dianjak ke belakang sebanyak langkah masa. Sebabnya tidak dapat dibezakan ialah elemen matriks
tidak berubah di bawah anjakan keseluruhan masa evolusi, kerana evolusi masa berkomut dengan Hamiltonian. Untuk ganjil, kita boleh menggunakan analisis untuk .
Kita ingin menunjukkan bahawa di suatu tempat dalam ruang Krylov ini, terdapat jaminan ada keadaan bertenaga rendah. Kita melakukan ini melalui keputusan berikut, yang diperoleh daripada Teorem 3.1 dalam [3]:
Tuntutan 1: terdapat fungsi sedemikian untuk tenaga dalam julat spektrum Hamiltonian (iaitu, antara tenaga keadaan tanah dan tenaga maksimum)...
- untuk semua nilai yang terletak jauh daripada , iaitu, ia ditekan secara eksponen
- ialah gabungan linear untuk
Kita berikan bukti di bawah, tetapi itu boleh dilangkau dengan selamat melainkan seseorang ingin memahami hujah penuh yang ketat. Buat masa ini kita fokus pada implikasi tuntutan di atas. Dengan sifat 3 di atas, kita dapat melihat bahawa ruang Krylov yang dianjak di atas mengandungi keadaan . Inilah keadaan bertenaga rendah kita. Untuk melihat kenapa, tulis dalam asas eigentenaga:
di mana ialah keadaan eigen tenaga ke-k dan ialah amplitudnya dalam keadaan awal . Dinyatakan dari segi ini, diberikan oleh
menggunakan fakta bahawa kita boleh menggantikan dengan apabila ia bertindak pada keadaan eigen . Ralat tenaga keadaan ini ialah
Untuk mengubah ini menjadi had atas yang lebih mudah difahami, kita mula-mula memisahkan jumlah dalam pengangka kepada sebutan dengan dan sebutan dengan :
Kita boleh mengehadkan atas sebutan pertama dengan ,
di mana langkah pertama mengikut kerana untuk setiap dalam jumlah, dan langkah kedua mengikut kerana jumlah dalam pengangka adalah subset jumlah dalam penyebut. Untuk sebutan kedua, pertama kita mengehadkan bawah penyebut dengan , kerana : menggabungkan semua kembali, ini memberikan
Untuk memudahkan apa yang tinggal, perhatikan bahawa untuk semua ini, mengikut definisi kita tahu bahawa . Tambahan pula mengehadkan atas dan mengehadkan atas memberikan
Ini berlaku untuk sebarang , jadi jika kita menetapkan sama dengan ralat sasaran kita, maka had ralat di atas menumpu ke arah itu secara eksponen dengan dimensi Krylov . Juga perhatikan bahawa jika maka sebutan sebenarnya hilang sepenuhnya dalam had di atas.
Untuk melengkapkan hujah, kita perlu memperhatikan bahawa di atas hanyalah ralat tenaga keadaan tertentu , bukan ralat tenaga keadaan bertenaga terendah dalam ruang Krylov. Namun, dengan prinsip variasi (Rayleigh-Ritz), ralat tenaga keadaan bertenaga terendah dalam ruang Krylov dibatasi oleh ralat tenaga mana-mana keadaan dalam ruang Krylov, jadi yang di atas juga merupakan had atas pada ralat tenaga keadaan bertenaga terendah, iaitu, output algoritma diagonalisasi krylov kuantum.
Analisis yang serupa seperti di atas boleh dijalankan yang juga mengambil kira hingar dan prosedur penghadan yang dibincangkan dalam buku nota. Lihat [2] dan [4] untuk analisis ini.
Lampiran II: Bukti Tuntutan 1
Berikut ini kebanyakannya diperoleh daripada [3], Teorem 3.1: biarkan dan biarkan menjadi ruang polinomial residual (polinomial yang nilainya di 0 adalah 1) berdarjah paling tinggi . Penyelesaian kepada
ialah
dan nilai minimum yang bersamaan ialah
Kita ingin menukar ini kepada fungsi yang boleh dinyatakan secara semula jadi dalam sebutan eksponen kompleks, kerana itulah evolusi masa nyata yang menjana ruang Krylov kuantum. Untuk melakukan ini, adalah mudah untuk memperkenalkan transformasi tenaga dalam julat spektrum Hamiltonian kepada nombor dalam julat berikut: takrifkan
di mana ialah langkah masa sedemikian sehingga . Perhatikan bahawa dan berkembang apabila bergerak jauh dari .
Sekarang menggunakan polinomial dengan parameter a, b, d ditetapkan kepada , , dan d = int(r/2), kita mendefinisikan fungsi:
di mana ialah tenaga keadaan tanah. Kita dapat melihat dengan menyisipkan bahawa ialah polinomial trigonometri berdarjah , iaitu, gabungan linear untuk . Tambahan pula, daripada definisi di atas kita ada bahawa dan untuk sebarang dalam julat spektrum sedemikian sehingga kita ada
Rujukan:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).